A few things recently have made me rethink my role with my clients recently in ways that I think are really interesting. One thing that has influenced me is the excitement coders have had in the last few months about the capabilities of AI generally, but specifically Claude. Another is the growing and improving list of tools that nonprofits are finding useful for raising money and tracking data. When I started working with nonprofits and their data about 13 years ago, the landscape was very different.
I’ve never thought of my job as Salesforce-specific, even though I have spent a lot of the last 13 years working inside of Salesforce. When I started, Salesforce’s API and ecosystem really didn’t have any competition in the nonprofit space. That’s not true anymore, which is wonderful. Realistically, I think most of the organizations that I work with that are using Salesforce today won’t be using it in 10 years. I’ve cleaned up a lot of failed migrations in the past, and I don’t want my clients to experience anything like that as they make changes in the future.
How does all of this effect my work? For one, when organizations come to me when they’re still exploring their options, I don’t push Salesforce at all. I’m happy to speak to the pros and cons and try and help them figure out what their specific pros and cons will be, but I don’t want to be the person who talked a nonprofit into Salesforce in 2025. I haven’t seen a CRM that is clearly better for most organizations, but it is easy to imagine one or two emerging in the next few years.
Another way this is effecting my work is that I want my clients to be prepared for big changes in the next few years. I don’t think any of us know what that those changes will look like, but there are some things to think about and focus on that can make any organization better prepared. I charge by the hour and don’t ever just go off doing work for my clients unless they want to pay for it, but it doesn’t cost them anything extra for me to approach the work with an updated mindset. With that in mind, here are some things I’m trying to think about when I help clients make decisions about what to invest time and money in.
Examining Complexity
All organizations have some complexity that is very specific to their own program, and supporting it requires investment of time and money. Whenever we’re talking about investing more time and money into supporting complexity, I want to make sure this is complexity that the organization really needs. Sometimes the complexity makes a big difference to the program and needs to be preserved. Sometimes it hasn’t been thought about for years and can be simplified. I’m not against continuing to invest in complexity in existing systems, but I want to make sure organizations consider how likely they are to still want that complexity in a few years to be part of their prioritization process.
Clean Data
While I don’t want to make many predictions about what the landscape will look like 10 years from now, I feel pretty confident saying that clean data will still be really important. Lots of change gets bogged down in dirty data, and I’m guessing the changes we’ll see in the next few years are no different in that way.
Explaining Data
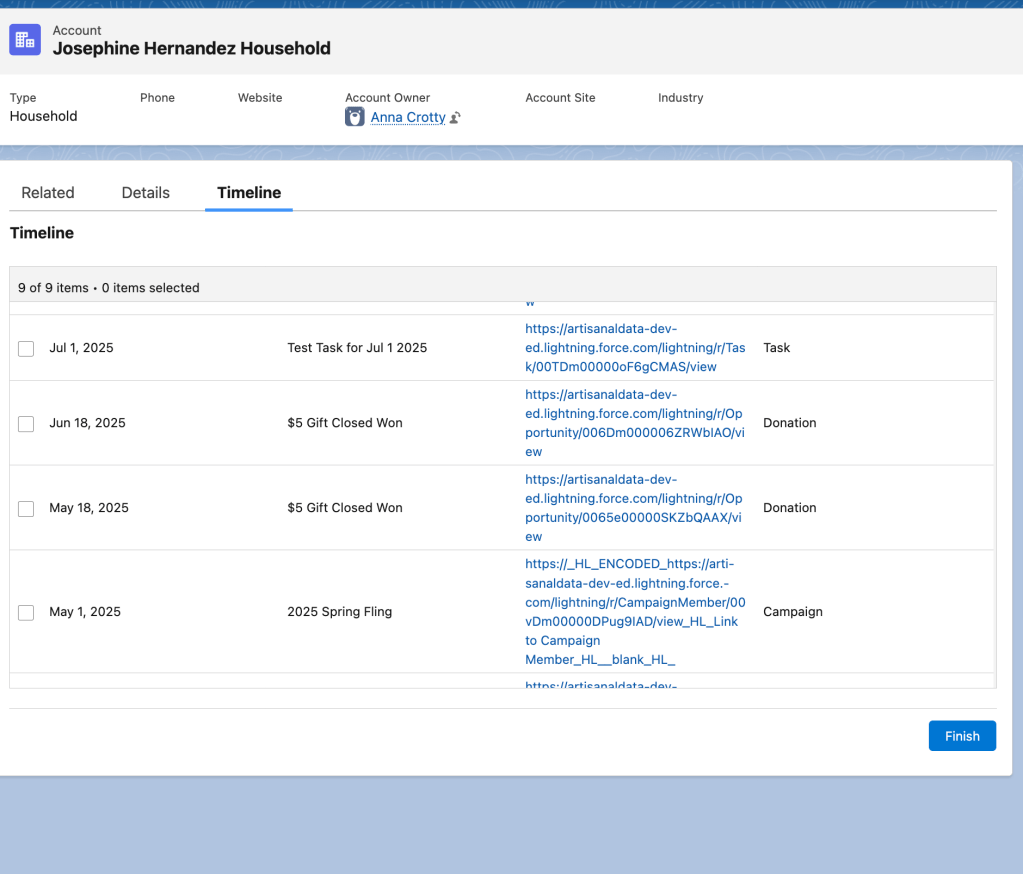
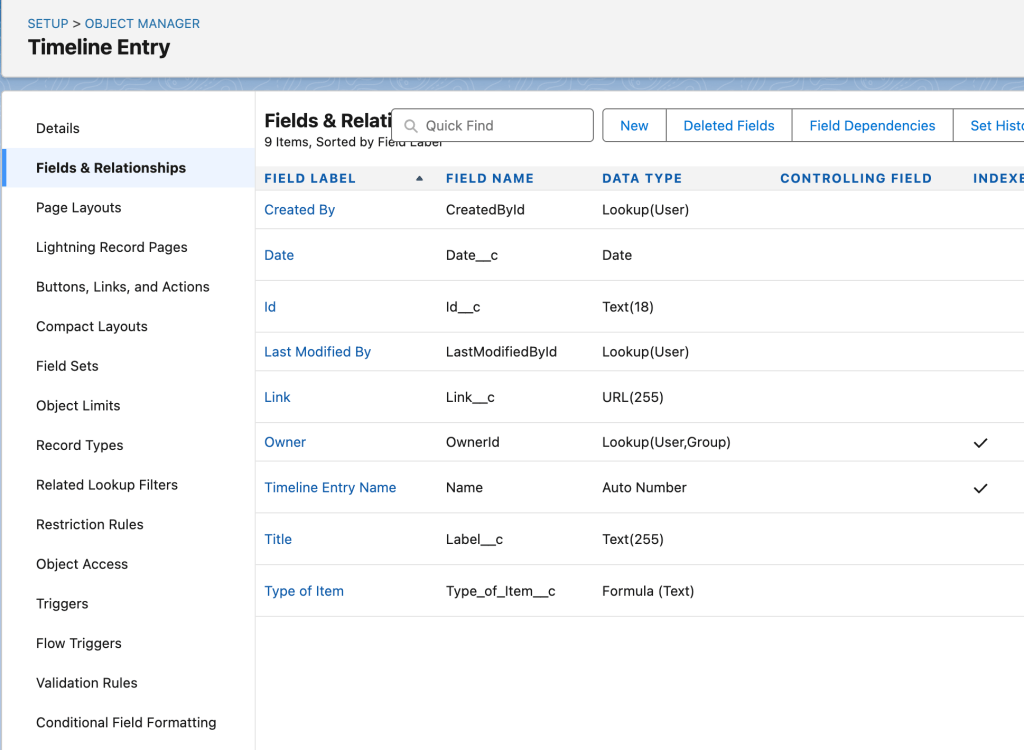
Talking about data with people who think about other things all day can be tough. People talk about how important documentation is a lot, but frequently people don’t talk about the kind of documentation that explains the data to people who aren’t familiar with it. That kind of documentation is the same kind that explains data to systems that aren’t familiar with it, whether that’s a new integration or a migrating to a different CRM or to something that isn’t a CRM but that replaces CRMs. The more we write down what data is important to us, where it lives and how it gets updated, the easier the changes will be.
Explaining Functionality
It is impossible to effectively change the tools you’re using if you don’t understand what your current tools are and aren’t doing for you now. This is also documentation, but most documentation doesn’t come at things from this angle. Lots of organizations have documentation of what project has been undertaken and even how the project was implemented, but documentation that explains what functionality an organization has an why is less common, but more useful for planning and evaluating change and understanding how effective an updated system is compared to the old one.
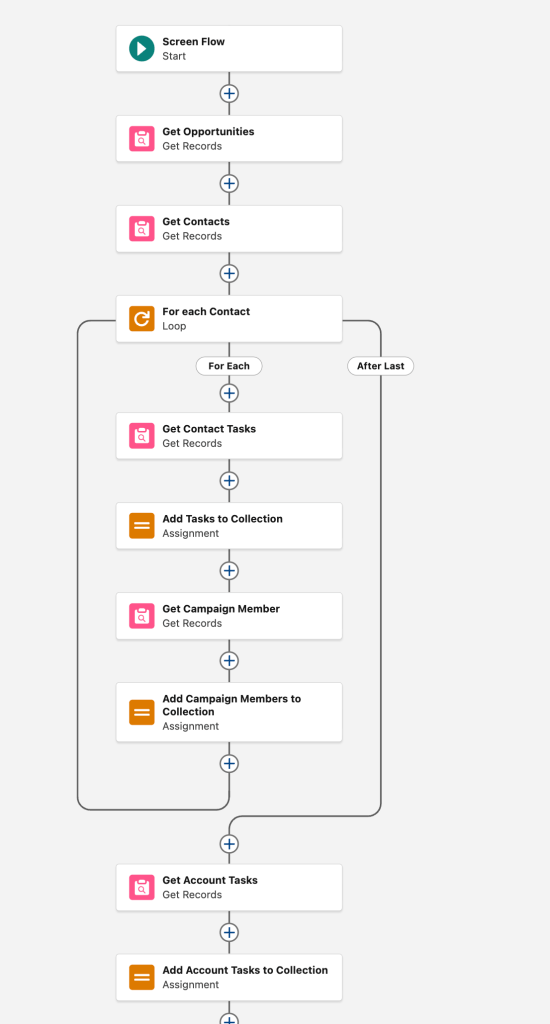
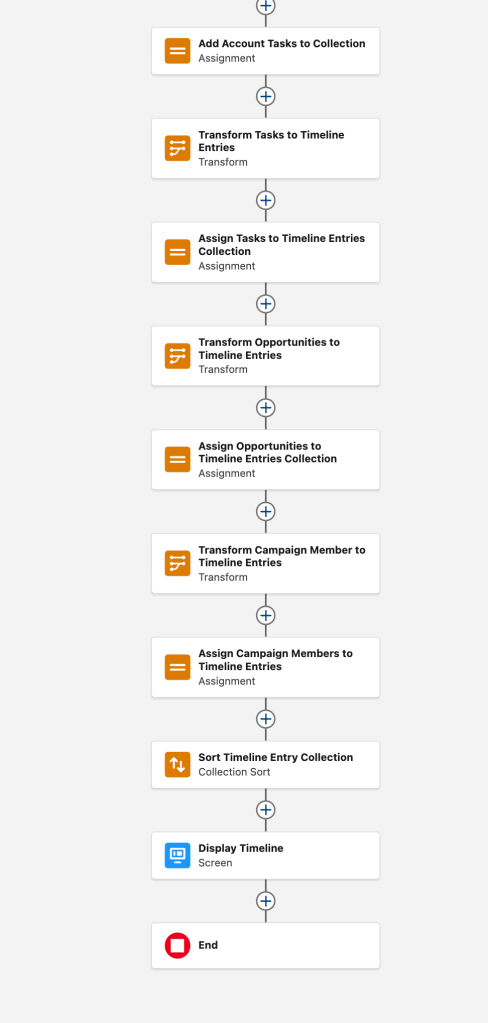
Logic Location
I’m using logic here as a shorthand for anything other than tables of data. It might be code that transforms Stripe transactions into a donation record, it might be automations that calculate a donor’s membership level, but all of that has to live somewhere. It has always been important to put that logic in the place that is the most maintainable and best able to handle the job. Now I think they should also be thinking about what location is going to be the easiest to migrate to something else.
Centering Humans
This last one isn’t a change for me at all, but I mention it because I think it is an important part of thinking about change. Even if you’re an executive dreaming about laying off all the humans who work for you, some part of your work is still ultimately about humans. Nonprofits serve humans, and nonprofits need humans to support them. When we’re thinking about what to invest time and money in and what is going to still be important years from now, I want to always come back to: what is going to work for the humans?